Сборка образа Docker - дело зачастую нетривиальное, однако собранный не лучшим способом образ может уничтожить большое количество времени на сборку и еще большее количество дискового пространства. В этой статье я хочу собрать лучшие рекомендации и методологии для оптимизации процесса сборки образа и его размера.
Ожидается, что вы знакомы с основами Docker и Dockerfile.
Приведенные в статье способы проверены на Docker 27.5.1 в связке с Buildkit 0.20.0!
¶ Оптимизация контекста сборки
Перед началом сборки Docker собирает контекст сборки - файлы, которые могут быть использованы при сборке контейнера. По умолчанию, Docker может копировать любые данные из директории, указанной в команде docker build. Попадание в контекст файлов разработки, таких как __pycache__ директории в Python, node_modules в NodeJS и подобных может серьезно замедлить старт сборки.
Помимо этого, неосторожные операции копирования могут привести к попаданию файлов окружения и конфигурации в образ, что может создать серьезные риски безопасности в случае, если образ хранится во внешнем репозитории или даже доступен публично для загрузки.
Для ограничения контекста сборки используется файл .dockerignore, имеющий формат аналогичный .gitignore. Файлы, указанные в нем не попадают в контекст сборки. Он может располагаться в корне директории проекта, который вы собираете или быть привязан к определенному Dockerfile. Для проекта на Python, использующего файл .env для конфигурации он может выглядеть следующим образом:
.env
__pycache__
*.pyc
С подробной документацией об использовании .dockerignore вы можете ознакомиться здесь
¶ Как работает сборка образа
Образ Docker основан на слоистой файловой системе, что значит что каждое действие во время сборки представляется отдельным слоем. При выполнении каждого слоя, накопленные данные передаются в следующий и так далее. Если во время сборки Docker выполняет то же действие в том же окружении, оно может быть сохранено в кеш и далее не выполняться повторно, что сокращает время сборки.
 Источник: dockerdocs
Источник: dockerdocs
Однако, если результат какого-либо из слоев изменится, кеш будет инвалидирован в измененном слое и слоях после него. Из примера выше, если файл Makefile или main.c будет изменен, то кеш инвалидируется на этапе COPY и сборка на этапе make build будет произведена заново.
¶ Как понять, что попало в образ?
При помощи сторонних утилит вы можете изучить, что попало (или не попало) в ваш образ в случае возникновения проблем. Для таких целей я рекомендую использование утилиты dive. Она доступна под многие системы (Mac, Windows, DEB/RPM-based дистрибутивы и др.), а также вы можете собрать ее из исходного кода или запустить при помощи Docker.
Далее, при помощи команды dive <название образа> вы можете изучить его слои, а также посмотреть, что изменилось при выполнении каждого слоя
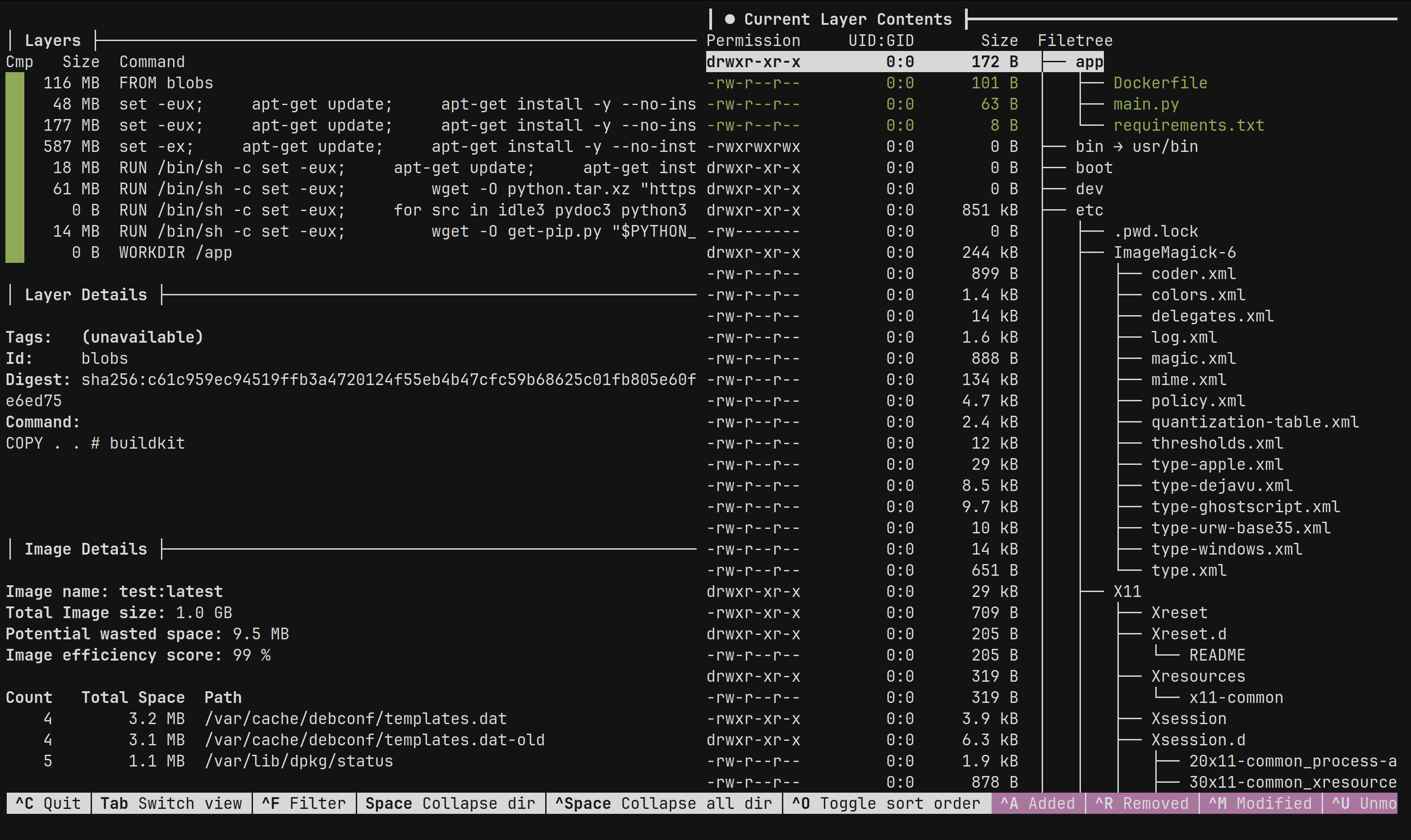 Интерфейс утилиты Dive при изучении образа
Интерфейс утилиты Dive при изучении образа
¶ Приемы оптимизации
¶ Выбор оптимальных образов
Коротко: большое количество образов имеют slim или alpine версии, которые могут отвечать вашим запросам при меньшем весе. Однако используйте их с осторожностью.
Самое простое, что можно сделать - это поменять базовый образ, который вы используете. Существует большое количество редакций образов, которые отличаются по следующим параметрам:
- Использование
muslвместоglibc- чаще всего используется при работе с компилируемыми языками, например Rust. Может быть частично или полностью несовместим с рядом инструментов и библиотек - Меньший набор встроенных библиотек (например,
python:<version>иpython:<version>-slim) - Базовый дистрибутив (например,
nginx:alpineиспользует Alpine Linux вместо Debian)
По различных причинам, эти образы могут вам не подойти. Например, библиотека uwsgi для Python требует дополнительные библиотеки при установке и без дополнительных вмешательств установится только на “полноценный” Python-образ, который тяжелее. Однако в таком случае вы можете использовать мультиэтапную сборку для сборки библиотек на более тяжелом образе и их перемещении в более легкий. Далее в статье вы увидите подобные примеры.
Пример мультиэтапной сборки для Python-проекта из файла requirements.txt
1 FROM python:3.11 AS builder
2 WORKDIR /app
3 COPY requirements.txt .
4 RUN pip wheel --no-cache-dir --no-deps --wheel-dir /app/wheels -r requirements.txt
5
6 FROM python:3.11-slim
7 WORKDIR /usr/src/app
8 COPY . .
9 COPY --from=builder /app/wheels /wheels
10 RUN pip install --no-cache /wheels/*
11 CMD "<ваша команда>"
А разработчики образа NodeJS вообще не рекомендуют использовать slim-образ, если у вас нет проблем с дисковым пространством - поскольку в этой редакции существует только минимальное окружение для запуска node.
Кроме того, alpine-версии образов также используют musl, что может серьезно повлиять на производительность или даже усложнить оптимизацию веса образа (источник 1, источник 2)
¶ При копировании файлов
Коротко: копируйте мало и по делу. Избегайте “тяжелых” действий под командами, которые копируют большое количество файлов. Ограничивайте контекст сборки при помощи .dockerignore
Рассмотрим пример с Python приложением из двух файлов: main.py с кодом и requirements.txt для установки зависимостей. Исходный Dockerfile выглядит так:
1 FROM python:3.12
2 WORKDIR /app
3 COPY . .
4 RUN pip install -r requirements.txt
5 CMD ["python", "main.py"]
Что не так?
- Не ясно, что вообще передается. Без корректного
.dockerignore(и даже с ним) в контейнер могут попасть “лишние” данные - Любые правки в код, которые попадут на 3 строке файла инвалидируют все действия после - в том числе установку зависимостей
В первую очередь, вынесем установку зависимостей до передачи файлов проекта - это позволит их поместить в кеш на более долгое время (в нашем случае - до тех пор, пока requirements.txt не поменяется). Однако нам нужен файл requirements.txt для установки библиотек, поэтому разделяем этап копирования исходного кода и зависимостей.
1 FROM python:3.12
2 WORKDIR /app
3 COPY requirements.txt .
4 RUN pip install -r requirements.txt
5 COPY main.py .
6 CMD ["python", "main.py"]
Теперь мы можем спокойно редактировать код и быстро пересобирать образ!
¶ При установке пакетов
Коротко: по необходимости делите действия на составные и зачищайте кеш пакетных менеджеров или используйте cache mounts
Допустим, вы собираете образ с графическим интерфейсом внутри (например, вы RDP поднимаете в Docker), рассмотрим такой пример:
1 FROM debian:bookworm
2 RUN apt-get update && apt-get install -y xfce4 xfce4-goodies
Что не так?
- В общем, этап рабочий - и будет кешироваться, но при модификации списка пакетов будут повторно загружаться все остальные (а у нас их тут весом под гигабайт), что не всегда приятно
- В образе контейнера остаются ненужные файлы, например, в нашем случае, кеш пакетного менеджера APT
С загрузкой тяжеловесных пакетов можно разобраться разбив загрузки на несколько этапов, однако проблема избыточного веса сложнее - в более старых версиях Docker мы могли бы удалять директории APT:
1 FROM debian:bookworm
2 RUN apt-get update
3 RUN apt-get install -y xfce4 xfce4-goodies
4 RUN apt clean all && rm -rf /var/lib/apt/lists/* /var/cache/apt/archives/*deb
Но при использовании новых версий Buildkit мы можем воспользоваться таким нововведением, как монтирование кеша (cache mounts). Идея заключается во временном монтировании директорий - благодаря чему не остается лишних файлов в контейнере. Монтированный кеш сохраняется между разными сборками, что ускоряет время сборки. Перепишем наш пример следующим образом:
1 FROM debian:bookworm
2 RUN --mount=type=cache,target=/var/cache/apt,sharing=locked \
3 --mount=type=cache,target=/var/lib/apt,sharing=locked apt-get update
4 RUN --mount=type=cache,target=/var/cache/apt,sharing=locked \
5 --mount=type=cache,target=/var/lib/apt,sharing=locked apt-get install -y xfce4 xfce4-goodies
Обратите внимание: от инвалидации кеша это не спасет. А также, монтировать директории придется на каждом этапе где это необходимо. То есть такой файл не будет успешно отработан:
1 FROM debian:bookworm
2 RUN --mount=type=cache,target=/var/cache/apt,sharing=locked \
3 --mount=type=cache,target=/var/lib/apt,sharing=locked apt-get update
4 RUN --mount=type=cache,target=/var/cache/apt,sharing=locked \
5 --mount=type=cache,target=/var/lib/apt,sharing=locked apt-get install -y xfce4 xfce4-goodies
6 RUN apt-get install -y sudo
7 # команда не будет отработана, т.к данные apt-get update не сохранены и пакет не будет найден
Как использовать монтирование кеша в своем сценарии?
Минимальная нотация: --mount=type=cache,target=<директория, которую кешируете>. Флаг sharing=locked нужен, если использование кеша между параллельными сборками единовременно может быть опасно и вы хотите этого избежать
¶ При сборке программ/переносимых файлов
Коротко: используйте мультиэтапную сборку с наименьшим допустимым образом
Рассмотрим пример со сборкой проекта на Haskell (да, несколько необычно, но поможет показать комбинацию подходов):
1 FROM haskell:9.4.7-buster
2 WORKDIR /project
3 COPY . .
4 RUN stack install
5 CMD ["/root/.local/bin/my-app-exe"]
Что не так?
- Титанический вес образа (3.4GB!) при сборке бинарного файла со статическими зависимостями
- В окружении остается большое количество артефактов разработки (например, исходный код), которые больше не нужны
В случае, если контейнер, используемый для сборки не нужен для запуска полученных файлов можно применить мультиэтапную сборку, в процессе которой выполняются действия в рамках одного базового образа (или нескольких, если этапов много) - а далее полученные файлы можно перенести в итоговый контейнер, который и будет сохранен. Перенесем наш собранный бинарный файл в контейнер с Debian для последующего запуска
1 # присваиваем контейнеру псевдоним builder для более простого обращения
2 FROM haskell:9.4.7-buster AS builder
3 WORKDIR /project
4 COPY . .
5 # вызываем сборку проекта через Stack (пакетный менеджер)
6 RUN stack install
7
8 FROM debian:bookworm
9 WORKDIR /project
10 COPY --from=builder /root/.local/bin/my-app-exe .
11 CMD ["my-app-exe"]
Вуаля! Итоговый размер контейнера - 122 мегабайта!
Дополнительное действие: Stack нуждается в сборке индекса библиотек перед тем, как их загрузить - поэтому вызов stack install может не кешироваться. Для этого, добавим вызов команды stack update для обновления индекса до копирования любых файлов (что позволит сохранить этап в кеше). Можете добавить подобные действия в свои сценарии сборки, если есть такая необходимость.
1 FROM haskell:9.4.7-buster AS builder
2 RUN stack update
3 WORKDIR /project
4 COPY . .
5 RUN stack install
6
7 FROM debian:bookworm
8 WORKDIR /project
9 COPY --from=builder /root/.local/bin/my-app-exe .
10 CMD ["my-app-exe"]
Похожим образом, например, можно оптимизировать сборку фронтенда на NodeJS и ее помещение в образ NGINX
1 FROM node:lts-slim AS builder
2 WORKDIR /project
3 COPY package.json package-lock.json ./
4 RUN npm install
5 COPY . .
6 RUN npm build
7
8 FROM nginx:stable-alpine
9 # копируем конфиг NGINX, написанный нами
10 COPY nginx.conf /etc/nginx/conf.d/site.conf
11 # копируем результаты сборки
12 COPY --from=builder /project/dist /frontend
¶ Если вы собираете много однотипных образов
Помимо этого, вы можете собирать промежуточный образ, из которого будут собираться остальные. Из рабочего примера - у меня есть проект с рядом микросервисов на Haskell, большая часть которых использует схожий технологический стек и ряд общих самописных библиотек. При сборке их образов, в первую очередь я собираю “родительский” образ в котором компилирую библиотеки и зависимости (благодаря чему они помещаются в кеш пакетного менеджера Stack). После этого, я запускаю мультиэтапную сборку каждого микросервиса, в которой остается собрать сам проект (поскольку зависимости уже собраны и берутся из кеша) и переместить его в легковесный образ Debian. Экспериментируйте и находите общие рутинные действия, которые можно объединить!
¶ Единовременное копирование файлов при помощи монтирования директорий
Помимо монтирования директорий для их кeширования, Buildkit поддерживает такую возможность как монтирование директории в рамках одного этапа сборки. Рассмотрим на примере приложения на Rust:
1 FROM rust AS builder
2 WORKDIR /project
3 COPY . .
4 # собираем проект
5 RUN cargo install --path .
6
7 FROM debian:bookworm
8 WORKDIR /project
9 # копируем бинарный файл
10 COPY --from=builder /project/target/release/app .
11 CMD ["./app"]
Не самый релевантный случай, однако мы можем избавиться от постоянного копирования файлов и ограничиться временным монтированием исходного кода. Монтирование директорий работает по аналогии с монтированием кеша, поэтому бинарный файл не будет сохранен - поэтому его нужно скопировать в другую директорию на том же этапе
1 FROM rust AS builder
2 WORKDIR /project
3 RUN --mount=type=bind,target=.,src=.,rw cargo install --path . && cp /project/target/release/app /
4
5 FROM debian:bookworm
6 WORKDIR /project
7 COPY --from=builder /app .
8 CMD ["./app"]
Синтаксис монтирования директорий
Минимальная нотация: --mount=type=bind,target=., где target - целевая директория монтирования в контейнере
Дополнительно можно указать доступность для записи (по умолчанию директория read-only) при помощи флага rw, а также указать источник монтирования помощи флага src.
¶ Заключение
В данной статье я собрал большинство полезных практик оптимизации скорости сборки образа и его итогового размера, которые сам знаю и использую. Надеюсь, эти советы помогут вам сделать использование контейнеров легче, проще, а иногда и дешевле!