Наверняка все из нас могли столкнуться с тем, что из Интернета по тем или иным причинам мог пропасть полезный для вас веб-ресурс или доступ к нему. Во избежание такой ситуации я изучил и подготовил сравнение инструментов, которые позволят сохранить контент со статических (и динамических в ряде случаев) сайтов для просмотра оффлайн с вашего устройства.
Дисклеймер!
Ваши действия по сбору данных с веб-ресурсов могут быть незаконны или расценены как DDOS-атака, будьте осторожны и внимательны при выполнении подобных действий, уважайте чужой сервер.
¶ wget
Стандартная для большинства дистрибутивов утилита обладает функционалом рекурсивной загрузки по HTML-страницам и их адаптации для относительного вида, что позволяет локально сохранить сайт. При помощи стандартного функционала можно настроить:
- Таймауты загрузок
- Список целевых доменов
- Фильтрацию URL по регулярным выражениям
- Список разрешенных и запрещенных для загрузки разрешений
Помимо составления дерева файлов, wget может выполнять запись в виде WARC-файла.
Что такое WARC?
WARC - специальный формат для архивирования веб-ресурсов, который сохраняет файлы и их метаданные для последующего открытия при помощи специальных программ.
¶ Однопоточная загрузка сайта
# загружать страницы сайта с перерывом в 0.5..1.5 секунды, таймаут загрузки - 30 секунд, три попытки на файл
Данные будут помещены в директорию с названием домена сайта.
¶ Пример использования на готовом сайте
-tили--tries- количество попыток--timeout- таймаут на загрузку файла включая все операции в секундах-U- используемое значение User-Agent--wait- время ожидания между загрузками в секундах--random-wait- включить случайный интервал ожидания между 0.5 и 1.5 от указанного--domains- список доменов через запятую для загрузки ресурсов--retry-connrefused- повторять загрузку в случае обрыва соединения--retry-on-http-error- коды ошибок, в случае возникновения которых будет выполняться повторная попытка-e robots=off- игнорировать файлrobots.txt. Используйте флаг только если уверены, что robots.txt препятствует сбору данных!--no-check-certificate- не проверять SSL-сертификаты--reject-regex- регулярное выражение URL, которое проверяет, игнорировать ли страницу. При наличии нескольких паттернов, паттерны можно указать через|(см. пример готовой команды)
¶ Загрузка в WARC-файл
Также можно сохранить результат загрузки в WARC-файл при помощи аргумента --warc-file с указанием пути архива (расширение файла будет добавлено автоматически). Также могут пригодиться следующие опции:
--no-warc-compression- не сжимать итоговый архив--warc-cdx- указать путь для генерации CDX файла для навигации в архиве--warc-max-size=<размер>- указать лимит WARC-файла (по умолчанию без лимита). Например,1G. После превышения размера будет создан новый архив.
¶ Пример загрузки сайта в WARC-файл
Команда сохранит данный сайт в WARC-файл по пути /tmp/test.warc.gz.
¶ wpull
Wpull - wget-совместимая утилита, написанная на Python Кристофером Фу (Christopher Foo). В отличие от wget, wpull поддерживает прерывание своей работы и продолжение при помощи ведения базы данных в виде файла, параллельную загрузку, а также интеграцию с youtube-dl и PhantomJS для загрузки видеороликов и активации JavaScript на странице, позволяя загружать не только статические сайты.
Wpull поддеживает только Python версии 3.4-3.5, поэтому самый простой способ воспользоваться утилитой - загрузить исполняемый файл с сайта Launchpad.
Внимание!
Активная разработка проекта прекращена, в связи с чем при использовании программы возможны различные баги и проблемы. При тестировании утилиты возникли проблемы с конвертацией ссылок при сохранении сайта в директорию, например.
¶ Пример использования
Большая часть опций wpull схожа с wget, с полным списком можно ознакомиться здесь. Пример команды, аналогичный предыдущему примеру:
Почему в примере не проверяется robots.txt?
На текущий момент утилита иногда обратывает файл robots.txt с ошибками, ссылка на Github issue. Для избежания этого поведения выключена обработка подобных файлов (опция --sitemaps) и URL robots.txt добавлено в исключение.
Сайт будет сохранен в одноименную с доменом директорию. Обратите внимание, что для загрузки “с нуля” потребуется удалить файл базы данных или поменять ее имя в команде. wpull также поддерживает сохранение результатов в WARC-файл при помощи аргумента --warc-file:
Будет создан архив /tmp/mrtstg.ru.warc.gz.
¶ grab-site
grab-site - преднастроеный веб-краулер от создателей wpull. В отличие от wpull, grab-site обладает веб-панелью для вывода логов, поддеживает более новые версии Python, позволяет реконфигурировать параметры загрузки сайтов (например, списки игнорируемых URL и количество параллельных загрузок) в процессе работы. Из минусов - нет поддержки прерывания и продолжения загрузки, а также сохранение только в WARC-файлы.
Самый простой способ запуска - docker-контейнер. Установите Docker на целевую систему, а далее выполните команду:
# может потребоваться sudo
Данная команда создаст контейнер warcfactory и директорию data в рабочей директории откуда была запущена команда, в ней будут храниться собранные данные. Для того, чтобы поменять это, замените ./data на желаемый вами каталог. После запуска контейнера вы сможете открыть веб-интерфейс по адресу http://127.0.0.1:29000.
Основные команды для управления контейнером следующие:
¶ Пример использования
Опции для команды сбора данных доступны в репозитории проекта, самая простая команда для запуска сбора данных выглядит следующим образом:
После запуска вы сможете увидеть вывод в терминале и в веб-интерфейсе системы. В случае слишком долгой работы, вы можете остановить процесс при помощи комбинации <CTRL-C>
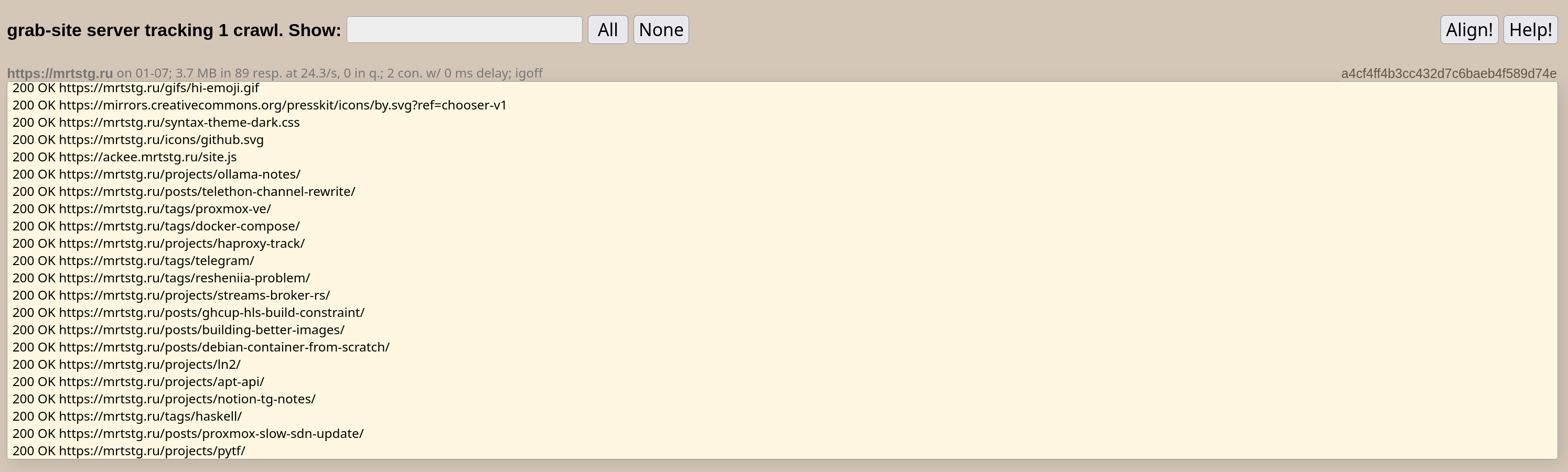 Пример веб-интерфейса
Пример веб-интерфейса
После завершения работы команды, файлы .warc.gz и .cdx вы можете найти в директории ./data/<домен>-<дата>-<хеш импорта из веб-интерфейса>, если вы не изменили путь хранения данных.
¶ Продвинутый пример
В случае необходимости, можно передавать параметры напрямую в wpull, работающий “под капотом”, при помощи опции --wpull-args, но лучше обходиться стандартными опциями. Таким образом можно интегрировать использование youtube-dl и PhantomJS.
¶ Игнорирование адресов
В отличие от упомянутых ранее способов, grab-site не принимает на вход регулярные выражения, но позволяет их добавить в процессе работы краулера (или импортировать файл при помощи опции --import-ignores, но это будет сложнее из-за работы из под Docker). Для этого в папке с данными сайтов найдите нужную директорию по имени и найдите там файл ignores и допишите туда регулярные выражения, например:
# набор правил для игнорирования сабреддитов, это пример - замените своими выражениями
^https?://(www|old)\.reddit\.com/gold\?goldtype=
# URLs with utm_ can (hopefully) be safely ignored because reddit also sends
# href=""s without the utm_ trackers.
^https?://(www|old)\.reddit\.com/r/[^/]+/.*[\?&]utm_
^https?://(www|old)\.reddit\.com/r/[^/]+/comments/[a-z0-9]+/[^/]+/[a-z0-9]+
^https?://(www|old)\.reddit\.com/r/[^/]+/comments/[a-z0-9]+.*\?sort=
^https?://(www|old)\.reddit\.com/r/[^/]+/comments/[a-z0-9]+/[^/]+/\.compact
^https?://(www|old)\.reddit\.com/r/[^/]+/(top|new|rising|controversial|gilded|ads)/.+[\?&]after=
^https?://(www|old)\.reddit\.com/r/[^/]+/related/
^https?://(www|old)\.reddit\.com/r/[^/]+/(gilded)?\.mobile\?
^https?://(www|old)\.reddit\.com/r/[^/]+/search/?\?
^https?://(www|old)\.reddit\.com/r/[^/]+/wiki/(revisions|discussions)/user/.+
^https?://(www|old)\.reddit\.com/user/[^/]+/(comments/)?.+[\?&]sort=
^https?://(www|old)\.reddit\.com/.+/\.rss$
\.reddit\.com/message/compose/?\?
^https?://(m|out|simple|amp)\.reddit\.com/
¶ HTTrack
HTTrack - утилита для Linux и Windows, написанная Ксавьером Роше (Xavier Roche) под лицензией GPL3. Она позволяет загрузить сайт локально, воссоздавая дерево файлов при помощи рекурсивного обхода ссылок страниц. Утилита поддерживает достаточную конфигурацию, например:
- Список разрешенных расширений
- Список разрешенных MIME-типов
- Загрузка через прокси-сервер
- Настройка количества параллельных процессов
Из недостатков можно отметить низкую скорость загрузки, а также периодические баги - например, зависание потока загрузки страницы, выявленное при тестировании, что снижает количество рабочих потоков и общую скорость работы.
¶ Пример использования
Установить HTTrack можно из стандартных пакетных репозиториев для большинства дистрибутивов - для установки доступна версия с веб-интерфейсом (webhttrack) и CLI-версия (httrack). Чтобы запустить временный веб-интерфейс введите:
 Пример веб-интерфейса
Пример веб-интерфейса
Для запуска CLI-утилиты:
¶ Какой инструмент лучше выбрать?
| Инструмент | Скорость работы | Интерфейс взаимодействия | Гибкость настройки | Возообновляемость загрузки | Вывод |
|---|---|---|---|---|---|
| grab-site | Высокая, многопоточная загрузка | CLI, отслеживание через веб-интерфейс | Динамическая настройка ряда параметров, возможность передачи параметров в wpull, используемый для загрузки | Не реализовано в основном проекте, есть отдельные форки | Наиболее удобный вариант для быстрых и массовых загрузок с возможностью доработки поведения на ходу |
| wget | Низкая (в сравнении), однопоточная загрузка | CLI | Достаточное количество параметров загрузки, настройки не меняются динамически | Нет, может быть частично воссоздана опциями загрузки | Хороший вариант для быстрого развертывания без необходимости быстрой загрузки с возможностью настройки поведения |
| wpull | Высокая, многопоточная загрузка | CLI | Аналогичная с wget, интеграция youtube-dl и PhantomJS, настройки не меняются динамически | Возообновление загрузки при помощи ведения базы данных | Неплохой вариант для параллельной загрузки, но возможно возникновение багов и ошибок. Также могут возникнуть затруднения с запуском в современном окружении |
| HTTrack | Средняя, могут возникать проблемы с многопоточной загрузкой | CLI, веб-интерфейс, GUI (для ряда систем) | Исчерпывающий набор параметров загрузки и фильтрации контента | Заявлен функционал обновления загруженного сайта | Простой и в меру удобный вариант для небольших задач краулинга |
¶ Заключение
В этой статье я постарался собрать основные и наиболее полезные методы сохранения данных из Интернета. В будущих статьях разберемся, как работать с WARC файлами, более сложными сайтами (с аутентификацией и динамическим содержимым) и продвинуто пользоваться описанными инструментами.